S3のライフサイクルルールでGlacierアーカイブされた大量のログファイルを復元するときに、S3バッチオペレーションを使って効率化する方法を紹介します。
なぜ復元にS3バッチオペレーションを使うのか
今回はS3バケットに保存されたALBのログを例に、Glacierアーカイブされた過去のログをAthenaでクエリできるようにする流れを説明します。
S3バケットに保存されたALBログをAthenaで集計できるようにしていても、ライフサイクルルールでGlacierアーカイブされた過去のログファイルはクエリ対象にすることはできません。
Glacierは低コストで保存できることと引き換えに、取り出すための復元処理に時間がかかるストレージクラスです。Glacierの中でもアクセスパターンによって複数のクラスが用意されていますが、総じて、めったにアクセスしなくなったファイルを長期間保存することを利用目的として提供されているストレージクラスです。
アーカイブされたオブジェクトの復元処理は、AWSマネジメントコンソールからでも可能です。
ただし、一度に選択できるオブジェクトは、画面に一覧表示されているオブジェクトのみとなります。
YYYY/MM/DDの階層で保存されているALBのログでは、数か月分のログを復元するのにかなりの繰り返し操作が必要になってしまいます。
AWS CLIを使って復元をするには、aws s3api restore-objectコマンドを使います。このコマンドはバケットとオブジェクトキーを指定して使うため、復元したいオブジェクトにひとつずつコマンドを発行するスクリプトを用意すれば、復元処理を開始することが可能です。
実際に3ヵ月分のログファイルを復元しようとしたところ、約55,000オブジェクトの復元が必要でした。大量のオブジェクトの復元処理を開始させるにはその分ループを回す必要があり時間がかかります。
効率よくコマンドを実行するには、適切な量で分割して平行実行できるようにしたり、復元開始に失敗したオブジェクトの記録などを、スクリプトで実装する必要があります。
上記のような、大量のS3オブジェクトに対して、同じような処理を効率的に行うためのサービスが、S3バッチオペレーションです。
S3バッチオペレーションでは、マニフェストファイルと呼ばれる、復元対象オブジェクトの一覧を指定してジョブを登録することで、一括で復元処理を開始させることができます。また、ジョブの実行状況や失敗したオブジェクトの情報も残すことができます。
S3バッチオペレーションにはGlacierアーカイブからの復元の他にも、オブジェクトのコピー、タグの置き換えなどの操作がAWSで用意されています。さらに、Lambda関数を呼び出して独自の処理をバッチ処理することも可能です。
当ブログでも、S3バケットのレプリケーションを開始するときにバッチオペレーションを実行する方法を紹介していますので、ご参照ください。
S3バッチオペレーション用のIAMロールを用意する
つづいて、実際にS3バッチオペレーションを実行する流れを説明します。
S3バッチオペレーションではユーザーに変わってバッチ操作をしてもらうため、専用のIAMロールを用意します。
まずはIAMポリシーを作成します。ここでは、policy-S3Batch-Restoreという名前のIAMポリシーを作成することとします。
ドキュメントのオブジェクトを復元: RestoreObjectにテンプレートが記載されており、次の3つのS3バケットへの許可ポリシーになっています。
TargetResource: 復元したいオブジェクトが保存されているS3バケットManifestBucket: マニフェストファイルを配置するS3バケットReportBucket: バッチ結果のレポートを配置するS3バケット
それぞれのバケットの役割ごとに許可が必要なアクションが異なりますが、すべて同じバケットを指定することも可能です。
{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "s3:RestoreObject" ], "Resource": "arn:aws:s3:::TargetResource/*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion" ], "Resource": [ "arn:aws:s3:::ManifestBucket/*" ] }, { "Effect":"Allow", "Action":[ "s3:PutObject" ], "Resource":[ "arn:aws:s3:::ReportBucket/*" ] } ] }
次に、IAMロールを作成します。ここでは仮にS3Batch-RestoreというIAMロールを作成することとします。
まずは、S3バッチオペレーションのサービスプリンシパルがIAMロールを引き受けることを許可するために、次の信頼ポリシーをアタッチします。
{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Principal":{ "Service":"batchoperations.s3.amazonaws.com" }, "Action":"sts:AssumeRole" } ] }
次に先ほど作成したpolicy-S3Batch-Restoreを許可ポリシーにアタッチします。
以上でIAMロールの準備は完了です。
マニフェストファイルを作成する
次に、復元対象のオブジェクトを指定するマニフェストファイルを作成します。
マニフェストファイルはCSV形式でつぎのようなフォーマットで記述します。
※保存されている最新バージョンのオブジェクトを復元する場合です
<S3バケット名>,<オブジェクトキー>
例:
Examplebucket,objectkey1 Examplebucket,objectkey2 Examplebucket,objectkey3 Examplebucket,photos/jpgs/objectkey4 Examplebucket,photos/jpgs/newjersey/objectkey5 Examplebucket,object%20key%20with%20spaces
S3バケットとオブジェクトパスを指定してGlacierアーカイブオブジェクトのマニフェストファイルを作成するスクリプト、create_manifest.shを作成しました。
#!/bin/bash # 引数チェック if [ "$#" -ne 2 ]; then echo "使用方法: $0 [バケット名] [フォルダパス]" exit 1 fi # 引数からバケット名とフォルダパスを取得 BUCKET=$1 FOLDER=$2 # マニフェストファイル名 MANIFEST="manifest.csv" # 一時ファイル名 TMPFILE=$(mktemp) # 初期化 NEXTTOKEN="null" # 追加オプション ##OPTIONS_LIST_OBJECTS="--encoding-type url --max-items 10 --profile hoge" OPTIONS_LIST_OBJECTS="--encoding-type url" # ファイルが存在するか確認 if [ -f "$MANIFEST" ]; then while true; do # ユーザーに入力を求める read -p "$MANIFEST exists. Do you want to append to this file? (y/n) " yn case $yn in [Yy]* ) break;; # 'y' または 'Y' が入力された場合、ループを抜ける [Nn]* ) exit;; # 'n' または 'N' が入力された場合、スクリプトを終了する * ) echo "Please answer yes or no.";; # その他の入力があった場合、もう一度入力を求める esac done fi # S3 からオブジェクトのリストを取得し、CSV 形式でマニフェストファイルを生成 # ページネーションを利用して全オブジェクトを取得 while : ; do if [ "${NEXTTOKEN}" == "null" ] ; then # aws s3api コマンド実行 aws s3api list-objects-v2 --bucket "${BUCKET}" --prefix "${FOLDER}" ${OPTIONS_LIST_OBJECTS} > ${TMPFILE} else # aws s3api コマンド実行 aws s3api list-objects-v2 --bucket "${BUCKET}" --prefix "${FOLDER}" --starting-token "${NEXTTOKEN}" ${OPTIONS_LIST_OBJECTS} > ${TMPFILE} fi # マニフェストに追記 cat ${TMPFILE} | jq -r --arg bucket "${BUCKET}" '.Contents[] | select(.StorageClass == "GLACIER") | [ $bucket , .Key] | @csv' >> ${MANIFEST} # NextTokenを取得 NEXTTOKEN=$(cat ${TMPFILE} | jq -r .NextToken) # NextTokenが取得できなかったら終了 if [ "$NEXTTOKEN" == "null" ] || [ -z "$NEXTTOKEN" ]; then break fi done # 一時ファイルを削除 #cp "$TMPFILE" ./ rm "$TMPFILE" echo "マニフェストファイルが生成されました: $MANIFEST"
たとえばs3://TargetResourceに保存されている2022/07 ~ 2022/09のログを対象にしたマニフェストファイルを作成する場合、以下のように3回スクリプトを実行します。
$ ./create_manifest.sh TargetResource AWSLogs/123456789123/elasticloadbalancing/ap-northeast-1/2022/07/ マニフェストファイルが生成されました: manifest.csv $ ./create_manifest.sh TargetResource AWSLogs/123456789123/elasticloadbalancing/ap-northeast-1/2022/08/ manifest.csv exists. Do you want to append to this file? (y/n) y マニフェストファイルが生成されました: manifest.csv $ ./create_manifest.sh TargetResource AWSLogs/123456789123/elasticloadbalancing/ap-northeast-1/2022/09/ manifest.csv exists. Do you want to append to this file? (y/n) y マニフェストファイルが生成されました: manifest.csv
作成したmanifest.csvを、IAMポリシーで指定したS3バケットManifestBucketにアップロードします。
S3バッチオペレーションにジョブ登録する
用意したIAMロールとマニフェストファイルを使って、S3バッチオペレーションのジョブを登録します。
AWSマネジメントコンソールのS3コンソールに移動し、左メニューのなかにある [バッチオペレーション] を選択し、[ジョブ作成] ボタンを押してください。
リージョンとマニフェストを選択
- バッチオペレーションを実行するリージョンを選択します
- マニフェスト形式にCSVを選択します
- マニフェストオブジェクトにアップロードした
manifest.csvのパスを入力して [次へ] を押します
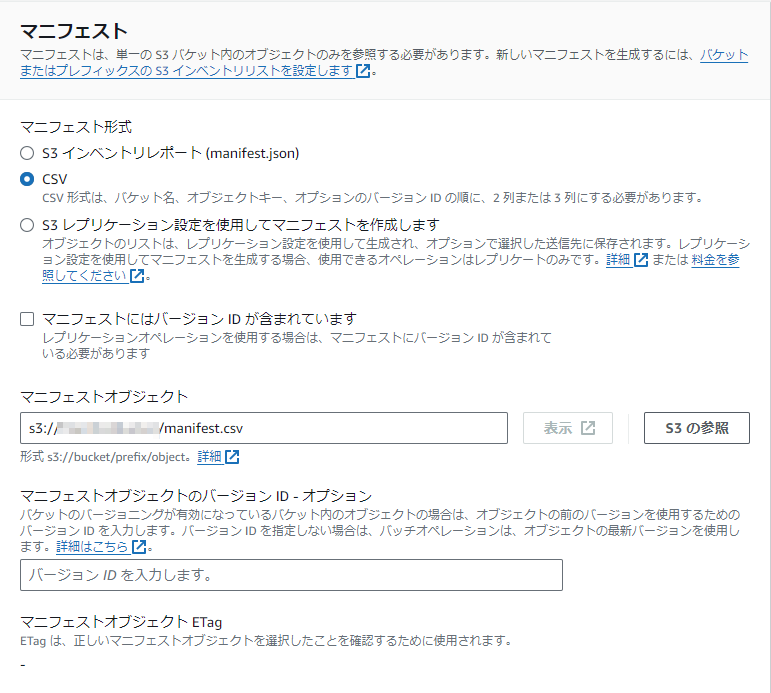
オペレーションを選択
- オペレーションタイプに復元を選択します
- ソースを復元にGlacier Flexible Retrieval または S3 Glacier Deep Archiveを選択します
- 復元されたコピーが利用可能な日数に、保持しておきたい日数を入力します
- 取得階層に一括取得を選択し、 [次へ] を押します
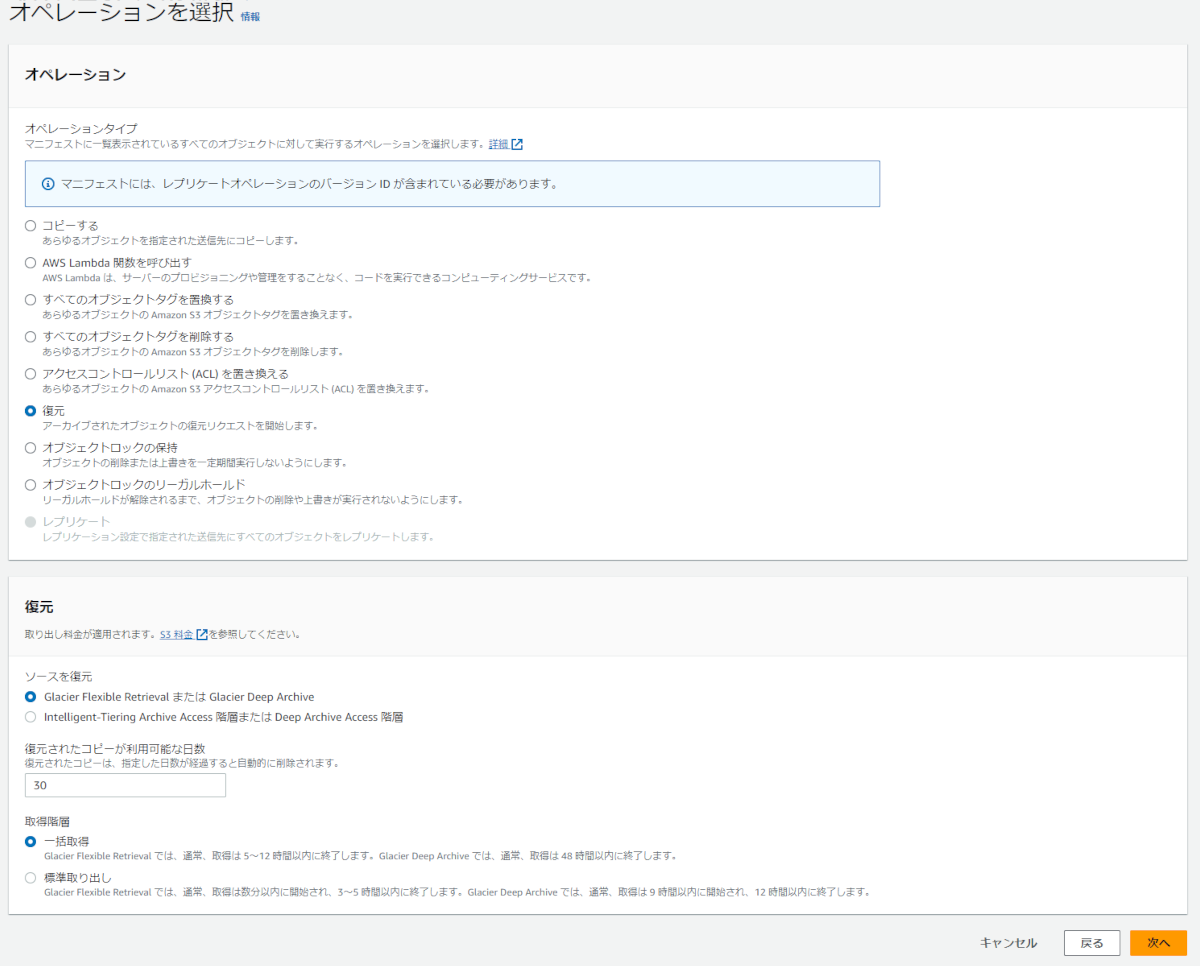
取得階層について
取得階層(retrieval tier)は、Glacierアーカイブされたオブジェクトを復元にかかる時間別に3段階用意されています。
Expedited(迅速)、Standard(標準)、Bulk(一括、大容量)があり、Bulk(一括、大容量)はもっとも時間がかかる代わりに復元処理自体に費用が掛かりません。
Expedited(迅速)、Standard(標準)はそれぞれ、復元オブジェクト数と復元オブジェクトサイズに対して費用がかかります。

S3バッチオペレーションで復元する場合は、Standard(標準)、Bulk(一括、大容量)のみ選択できます。
時間に余裕があれば、Bulk(一括、大容量)がお得ですが、少しでも早くオブジェクトを使いたい場合は、Standard(標準)を検討してください。
また、上記の表にあるとおり、S3バッチオペレーションを利用してStandard(標準)で取り出す場合、通常の取り出しよりも大幅に時間を削減できるようになっているので、S3バッチオペレーションを利用するメリットが大きいといえます。
各取得階層の料金は、S3料金ページの [ストレージとリクエスト] タブのリクエストとデータ取り出しに記載されていますので、ご確認ください。
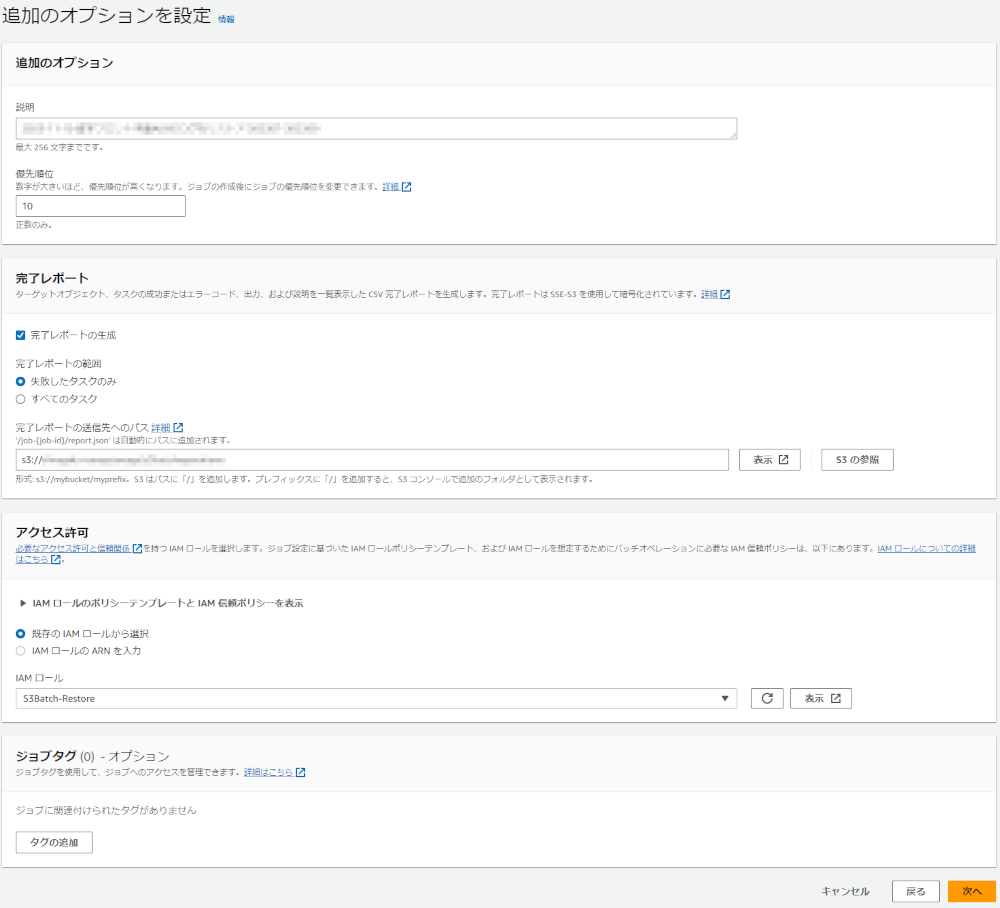
追加のオプションを設定
- 説明に、ジョブのタイトルを入力します
- 完了レポートの作成にチェックを入れます
- 完了レポートの範囲に失敗したタスクのみを選択します
- 要件によってはすべてのタスクを選択してください
- 完了レポートの送信へのパスに、IAMポリシーで指定したS3バケット
ReportBucketのパスを入力します - アクセス許可に既存のIAMロールから選択を選択します
- IAMロールに最初に作成した
S3Bach-Restoreを選択します
- IAMロールに最初に作成した
[次へ] を押します
確認ページに遷移するので [ジョブの作成] を押します
ジョブを実行する
ジョブの作成が完了すると、バッチオペレーションのジョブ一覧画面に遷移します。
ステータスが新規となっているジョブが作成されているはずです。
しばらく待つと、ステータスが実行のための確認待ちに変わり、オブジェクトの合計項目に、数字が記載されます。

このステータスになったら、ジョブを実行します。
- ジョブIDを押してジョブ詳細画面に移動します
- [ジョブを実行] ボタンを押します
- ジョブ実行確認画面に遷移するので、左下の [ジョブを実行] を押します
- ジョブ詳細画面に移動するのでステータスが完了になるのを待ちます
- 各ジョブステータスの説明はジョブステータスに記載があります
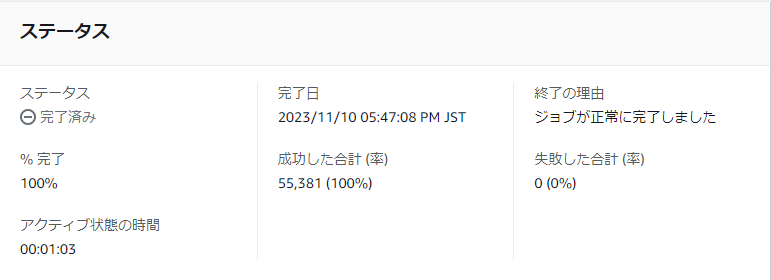
成功率が100%でなければレポートが出力されています。
レポートのフォーマットは例: S3 バッチ操作完了レポートに記載されています。
オブジェクトの復元を確認する
S3バッチオペレーションのジョブステータスが完了になったからといって、オブジェクトにアクセスできるようになったわけではありません。
CLIでいうところのaws s3api restore-objectコマンドの実行が完了している状態なので、ここから各オブジェクトの復元処理が完了するまで待つ必要があります。
オブジェクトの復元が完了しているかどうかは、各オブジェクトのステータスを確認する必要があります。
復元処理が完了していないオブジェクト一覧を出力するスクリプトcheck_restore_status.shを作成しました。
#!/bin/bash # 引数チェック if [ "$#" -ne 2 ]; then echo "使用方法: $0 [バケット名] [フォルダパス]" exit 1 fi # 引数からバケット名とフォルダパスを取得 BUCKET=$1 FOLDER=$2 # リストア進行中出力先 OUTPUTFILE="PendingRestoreFiles_$(date "+%Y%m%d-%H%M%S").csv" # 一時ファイル名 TMPFILE=$(mktemp) # 初期化 NEXTTOKEN="null" # 追加オプション ##OPTIONS_LIST_OBJECTS="--encoding-type url --max-items 10 --profile hoge" OPTIONS_LIST_OBJECTS="--encoding-type url" # S3 からオブジェクトのリストを取得し、CSV 形式でマニフェストファイルを生成 # ページネーションを利用して全オブジェクトを取得 while : ; do if [ "${NEXTTOKEN}" == "null" ] ; then # aws s3api コマンド実行 aws s3api list-objects-v2 --bucket "${BUCKET}" --prefix "${FOLDER}" --optional-object-attributes="RestoreStatus" ${OPTIONS_LIST_OBJECTS} > ${TMPFILE} else # aws s3api コマンド実行 aws s3api list-objects-v2 --bucket "${BUCKET}" --prefix "${FOLDER}" --optional-object-attributes="RestoreStatus" --starting-token "${NEXTTOKEN}" ${OPTIONS_LIST_OBJECTS} > ${TMPFILE} fi # リストア進行中 cat ${TMPFILE} | jq -r --arg bucket "${BUCKET}" '.Contents[] | select(.RestoreStatus.IsRestoreInProgress) | [ $bucket , .Key] | @csv' >> ${OUTPUTFILE} # NextTokenを取得 NEXTTOKEN=$(cat ${TMPFILE} | jq -r .NextToken) # NextTokenが取得できなかったら終了 if [ "$NEXTTOKEN" == "null" ] || [ -z "$NEXTTOKEN" ]; then break fi done # 一時ファイルを削除 # cp "$TMPFILE" ./ rm "$TMPFILE" echo "リストア進行中オブジェクト件数: $(wc -l ${OUTPUTFILE})"
実行すると、PendingRestoreFiles_YYYYMMDD-hhmmss.csvというリストア未完了オブジェクト一覧を出力します。
レコード件数が0件になればすべてのオブジェクトの復元が完了しています。
$ ./check_restore_status.sh TargetResource AWSLogs/123456789123/elasticloadbalancing/ap-northeast-1/2022/07/ リストア進行中オブジェクト件数: 344 PendingRestoreFiles_20231110-232158.csv $ ./check_restore_status.sh TargetResource AWSLogs/123456789123/elasticloadbalancing/ap-northeast-1/2022/08/ リストア進行中オブジェクト件数: 335 PendingRestoreFiles_20231110-232222.csv $ ./check_restore_status.sh TargetResource AWSLogs/123456789123/elasticloadbalancing/ap-northeast-1/2022/09/ リストア進行中オブジェクト件数: 327 PendingRestoreFiles_20231110-232239.csv
復元オブジェクトをAthenaでクエリできるようにする
この状態でAthenaで直接クエリできるようにするには下記の制約事項があります。
- 復元された Amazon S3 Glacier オブジェクトのクエリは、Athena エンジンバージョン 3 でのみサポートされています。
- この機能は Apache Hive テーブルでのみサポートされています。
- Athena はオブジェクトを復元しないため、データをクエリする前にオブジェクトを復元する必要があります。
残念ながら、ALBのログはHive形式で保存されていないので、このままではAthenaでクエリすることができません。
通常の読み取りができるようにするために、オブジェクトのストレージクラスをStandardに変更する必要があります。
Standardに変更するには、既存のオブジェクトを上書きするか、オブジェクトを別の場所にコピーするかの2つの方針があります。
既存のオブジェクトを上書きする場合、Athenaでこれまでと同じテーブルを使ってシームレスにクエリが可能です。Glacierアーカイブされる前のデータと合わせて集計したい場合は便利です。
しかし、オブジェクトの最終更新日が上書きした日に更新されるので、ライフサイクルルールの経過日数がリセットされます。
予定よりも長期間ログが保存されることになるので、データ量によっては費用への影響が懸念されます。
一方オブジェクトを別の場所にコピーする場合は、Athenaに新たにテーブルを作成する必要があります。
既存テーブルとスキーマ定義が同じなので、大きな手間ではありませんが、既存テーブルのデータと合わせて集計したい場合は、クエリ側の工夫が必要となります。
古い日付のログ集計が終わり次第、コピーしたオブジェクトを削除してしまえば、費用への影響を抑えることができます。
AWS CLIで復元が完了しているGlacierオブジェクトをコピーするときは、aws s3 cp --force-glacier-transferというオプションで実行します
AWS re:PostのFAQで詳しく解説されているので、ご参照ください。
コマンドだけ要約すると以下のとおりです。
既存のオブジェクトを上書 $ aws s3 cp s3://awsexamplebucket/dir1/ s3://awsexamplebucket/dir1/ --storage-class STANDARD --recursive --force-glacier-transfer オブジェクトを別の場所にコピー $ aws s3 cp s3://awsexamplebucket/dir1/ s3://awsexamplebucket/dir2/ --recursive --force-glacier-transfer
オブジェクトを別の場所にコピーする例では同じバケットの別ディレクトリにコピーしていますが、別のバケットを指定することも可能です。
既存のオブジェクトを上書した場合は、既存のログ集計テーブルで復元した日付を指定してクエリすると、集計結果が出力されるようになります。
オブジェクトを別の場所にコピーした場合は、Athenaに古い日付のログを集計する用のテーブルを作成して、クエリに成功するかを確認してください。
まとめ
GlacierへのアーカイブはS3ライフサイクルルールで簡単に設定できます。
コストを最適化するために導入している方も多いかと思いますが、取り出しは頻繁には起こらないので、いざ実際に大量のオブジェクトを復元しようとすると、どうやるんだっけと戸惑ってしまうかもしれません。
今回紹介した、S3バッチオペレーションをつかってGlacierオブジェクトを効率的に復元する方法がお役にたてば幸いです。
S3バッチオペレーションの実行には料金が発生します。
S3料金ページの [管理と洞察] タブのS3バッチオペレーションの料金に記載されています。
実行したジョブ数と処理したオブジェクト数に課金されていることに注意が必要です。なるべくひとつのジョブにまとめて実行することでコストを最適化できます。